Conceptos de Arquitectura de Computadoras
Para comprender mejor los conceptos de procesos e hilos, se debe dar un pequeño repaso a conceptos de arquitectura de computadoras y cómo un programa es ejecutado en el procesador.
¿Por qué el tipo y tamaño de las variables es importante?
En la actualidad existen lenguajes como Javascript, Python, Elixir, entre otros, donde no es necesario ser explícito para establecer el tipo de cada variable ni el tamaño que estas usan en memoria, ya que el intérprete de cada lenguaje es quien toma esa decisión.
Al momento de utilizar lenguajes de programación de sistemas como
C, Ada o Rust, entre otros, se debe ser más explícito. Estos
lenguajes obligan a declarar las variables incluyendo su tipo y permiten
mayor granuralidad en el manejo de la memoria. A diferencia de los lenguajes interpretados donde solamente puede ser necesario un tipo llamado "Number", en los lenguajes de sistemas existe la diferenciación
entre enteros, punto flotante y punto fijo, además una granularización
sobre cuánta memoria (8 bit, 16bit, 32bit, 64bit) cada tipo utilizará
para almacenar los datos. Incluso estos lenguajes pueden permitir especificar si el número es positivo o negativo, aumentando el control sobre el uso de la memoria.
La memoria de un computador es finita y el propósito de estos tipos es especificar exactamente cuánto espacio en memoria es necesario para representar la información que el programa utiliza.
Un bit es la unidad mínima de valor que puede tener dos estados 0 y 1. El computador representa los datos en una secuencia de ocho bits llamada byte (00000000 a 11111111 en binario, 00 a FF en hexadecimal, 0 a 255 en decimal). Es decir que un byte (255 valores posibles) es el mínimo de bits usado para almacenar algo y por eso es que se utilizan múltiplos de ocho (8, 16, 32, 64) para representar los números.
El programador al delegar la gestión de memoria a un lenguaje interpretado, pierde la capacidad de optimizar la memoria usada, provocando que muchas veces un lenguaje interpretado utilice más memoria de la necesaria para la misma operación que en un lenguaje de sistemas. Los lenguajes interpretados deben almacenar el dato y metadatos (tags) asociados para poder realizar su gestión de tipos y memoria interna. Esto no solo aumenta la cantidad de memoria necesaria, también aumenta la cantidad de operaciones (leer, escribir, comparar) que la CPU debe realizar. El intérprete entonces debe ejecutar todos esos pasos adicionales no relacionados al código del programador, lo que en contraste con lenguajes compilados no es necesario debido a que se ha dado la información de tipos y memoria con antelación.
El compilador de un lenguaje de sistemas puede generar código máquina más eficiente, sin necesidad de validaciones adicionales. Ésta es una de las principales razones por la que los lenguajes de tipado dinámico son mucho más lentos y requieren mayor cantidad de recursos (memoria, CPU) que los lenguajes de sistemas. Sin embargo, los lenguajes de sistemas requieren de mayor cautela y rigurosidad en su programación, por ejemplo un arreglo que necesite de una cantidad variable de elementos (crecer o reducir su cantidad de elementos dinámicamente) debe usar estrategias de gestión de memoria (regiones de memoria como Heap y Stack, tamaño del arreglo).
Componentes de una CPU
Una CPU, o unidad central de procesamiento, es un componente de hardware y la unidad computacional central de un servidor. La CPU es el componente principal que procesa las señales y hace posible la computación. Actúa como el cerebro de cualquier dispositivo de computación. Obtiene instrucciones de la memoria, realiza las tareas necesarias y envía la salida a la memoria. Maneja todo tipo de tareas de computación necesarias para que el sistema operativo y las aplicaciones se ejecuten. (AWS, 2024).
Reloj (Clock)
La CPU se basa en una señal de reloj para sincronizar sus operaciones internas. El reloj genera un pulso constante a una frecuencia específica y estos ciclos de reloj coordinan las operaciones de la CPU. La velocidad del reloj se mide en hercios (Hz) y determina cuántas instrucciones puede ejecutar la CPU por segundo. Las CPU modernas tienen velocidades de reloj variables que se ajustan en función de la carga de trabajo para equilibrar el rendimiento y el consumo de energía. (AWS, 2024).
Por ejemplo el reloj necesario para el famoso procesador 6502 requiere de 1Mhz (Usado en sistemas como la Atari, Nintendo y Apple II). Mientras que procesadores modernos como el i9 pueden llegar a los 6.20 Ghz.
Registros (Registers)
Los registros son pequeñas ubicaciones de almacenamiento de memoria de alta velocidad dentro de la CPU. La cantidad de estos depende de cada procesador y su arquitectura. Contienen datos en los que la CPU está trabajando en ese momento y facilitan un acceso rápido a los datos. Las CPU tienen varios tipos de registros, como:
-
Registros de uso general que contienen datos operativos
-
Registros de instrucciones que contienen la instrucción actual que se está procesando
-
Un contador de programas que contiene la dirección de memoria de la siguiente instrucción que se va a recuperar
Los registros proporcionan tiempos de acceso más rápidos que otros niveles de memoria, como la RAM o la memoria caché (AWS, 2024).
En palabras simples, los registros son como variables usadas por el procesador que guardan información necesaria para las tareas a realizar por el mismo, al estar más cercanas al CPU tienen mayor velocidad que la memoria o cache. Algunos registros pueden ser de uso general mientras que otros son de un uso específico como el Program Counter.
Contador de Programa (Program Counter)
El contador de programa, también conocido como puntero de instrucción o simplemente PC, es un componente fundamental de la unidad central de proceso (CPU) de un computador. Es un registro especial que lleva la cuenta de la dirección de memoria de la siguiente instrucción a ejecutar en un programa (Lenovo, s.f).
Banderas de Ejecución (Execution Flags)
Cuando el procesador realiza operaciones, tiende a retornar no solo el resultado de la operación. También retorna banderas (flags) de ejecución (execution) que permiten realizar condicionales. Por ejemplo si dos registros son substraidos, se da el resultado pero también el estado como si fue cero o es mayor o menor a cero. Esto permite programar condicionales dependiendo de estos estados. Es como si fueran registros de un bit que almacenan un resultado comparativo de la operación.
Pila (Stack)
Una pila (stack) es una estructura de datos donde el último elemento en entrar es el primero en salir (Last in - first out, LIFO). Es como una pila de platos; No se puede quitar una plato del medio sin interrumpir toda la pila. (Lenovo, s.f). En la informática una pila tiene un tamaño máximo y si se excede ocurre lo que se conoce como "saturación de pila" (stack overflow).
En términos de procesadores la pila corresponde a la "pila de ejecución" (execution stack), también conocida como "pila de programa" (program stack), incluso como "pila de hardware" (hardware stack). Cuando se ejecuta un programa, técnicamente no hay limitaciones donde se escribe dentro de la memoria, si bien se puede definir el tamaño, la ubicación en memoria puede ser totalmente aleatoria y arbitraria. Pero hacer esto es ineficiente, provocando que exista mucho espacio desperdiciado.
El sistema operativo es el intermediario entre los programas y el hardware. Cuando un programa se ejecuta, el sistema operativo no permite que este almacene los datos en cualquier parte de la memoria, debido a que otros programas podrían estar utilizando ese espacio. El programa debe solicitar al sistema operativo un espacio de memoria y este buscará el espacio disponible para que el programa escriba y lea sus datos.
Si un programa intenta leer un espacio de memoria que esta fuera de los límites que el sistema operativo le otorgó, el sistema operativo tiene la facultad de terminar el programa (por razones de seguridad), dándo origen a los errores conocidos como "Segmentation Fault, Core Dumped". Es por este motivo que el sistema operativo asigna la memoria en bloques (memory chunk) que los programas pueden usar para leer y escribir.
Si un programa no administra bien su memoria y almacena sus datos de forma desordenada, podría necesitar más bloques de memoria. Eventualmente esto podría causar lo que se conoce como "Fragmentación Externa" (external fragmentation) donde existe memoria libre suficiente, pero no se puede almacenar más datos debido a que no existe el suficiente espacio continuo para formar un nuevo bloque de memoria. El solicitar más memoria puede ser muy costoso en términos de desempeño, lo que da origen a la recomendación de usar el Heap lo menos posible.
El sistema operativo otorga bloques de memoria para los programas, pero no tiene control sobre cómo los programas usan la memoria asignada. Lo único que conoce es que la región de memoria está siendo utilizada por un programa y si otro programa necesita más bloques de memoria, el sistema operativo debe buscar un espacio libre en otro sector. Como la memoria disponible es un recurso limitado, los sistemas operativos modernos tienen mecanismos para abordar la falta de memoria y reemplazarla con espacio en el disco, como si fuera memoria adicional. Por ejemplo en sistemas Linux se conoce como partición "Swap". Este concepto se conoce como "Memoria Virtual" y es una ilusión creada por el sistema operativo para aparentar tener más memoria de la disponible físicamente.
Depender del almacenamiento como memoria adicional es más lento que utilizar la memoria RAM, por lo que se debe utilizar este mecanismo con cautela. A pesar de que actualmente existe una cantidad gigante de almacenamiento, en comparación con la década de los 90s, el criterio de desempeño sigue siendo importante. La memoria puede ser un cuello de botella, aún considerando el poder de las CPU actuales, ya que obtener datos de la memoria tiene un costo de tiempo considerable, para esto los fabricantes de procesadores han elaborado lo que se conoce como Cache, el cual es como una memoria pequeña dedicada dentro del procesador, el cual tiene una copia de una región de la memoria, permitiendo a la CPU obtener datos para sus operaciones sin pasar por la memoria principal, pero la memoria principal será utilizada si el dato no está presente en el Cache. La labor de decidir que región de la memoria se almacena en el Cache depende del hardware y no del sistema operativo.
El desarrollador tiene la responsabilidad de utilizar estructuras de datos y la memoria adecuadamente para tengan mayor probabilidad de ser transferidas a Cache, permitiendo mayor velocidad de lectura y escritura por que está más cerca de la CPU, lo que se conoce como localidad (locality).
Entonces la pila es una estructura de datos adecuada para almacenar los datos de forma compacta y ordenada. Cada vez que un programa declara una variable, su valor es apilado en la región de memoria asignada. Un registro en la CPU almacena el puntero de la pila que indica el dato superior (el registro permite obtener el puntero sin ir a buscar en memoria o cache). Esto hace que las operaciones en el Stack sean muy rápidas gracias al puntero de direcciones. Comunmente solo basta con sumar uno a la posición y se tendrá el siguiente espacio de memoria disponible. Esta facilidad y velocidad de uso contratasta con el Heap, el cual no es tan rápido ni sencillo de utilizar.
Las limitaciones de la pila (Stack) está en que no es muy flexible para crecer o reducir dinámicamente su tamaño, es por esto la importancia de tener una buena gestión de memoria, compactando los datos y especificando sus tipos adecuadamente para que los compiladores organicen los datos de forma eficiente y predecible en el Stack. Además el Stack opera en un solo hilo, dando una limitación cuando se intenta compartir memoria entre hilos. Este tipo de limitaciones son solucionadas por el Heap.
Montículo (Heap)
El montículo (heap), también conocido como "almacenamiento libre". Es una estructura dinámica de datos o área de memoria para lograr asignación dinámica de memoria durante la ejecución de un programa. Permitiendo asignar memoria y liberarla de forma flexible, según sea necesario.
La gestión de memoria dinámica requiere de dos tipos de operaciones; la petición y la liberación de memoria. El ciclo es sencillo, cuando se precisa almacenar un nuevo dato, se solicita tanta memoria en bytes como sea necesaria, y una vez que ese dato ya no se necesita la memoria se devuelve para poder ser reutilizada. Este esquema se conoce como "gestión explícita de memoria" pues requiere ejecutar una operación para pedir la memoria y otra para liberarla (Universidad Carlos III de Madrid, s.f.). En el lenguaje C estas funciones son: malloc, calloc, free y realloc.
El Heap es necesario debido a que el Stack si bien permite almacenar los datos de forma compacta y mejorar el desempeño, tiene limitaciones debido a que el Stack no permite acomodar dinámicamente los datos. Por ejemplo en un arreglo con elementos definidos no permite añadir nuevos, solo sobre escribirlos. Esto significa que puede gatillar un error de desbordamiento (Stack Overflow) si se intenta añadir más elementos de lo originalmente definido. El Heap permite solicitar memoria virtualmente ilimitada, utilizando llamadas al sistema, lo que permite al Heap almacenar grandes cantidades de datos. Esto trae la necesidad de administrar manualmente la memoria asignada (en los lenguajes de programación de sistemas). Es común la estrategia de almacenar solamente los punteros de memoria (direcciones de memoria, memory addresses) en el Stack y los datos asociados a dichos punteros en el Heap. Un puntero solo representa una dirección de memoria y no contiene la información ni los datos del largo o tamaño de los datos.
¿Es posible la fragmentación en el Heap?
Con el Stack sabemos que existe la fragmentación externa, donde se requiere más bloques de memoria a pesar de que se tiene memoria disponible, debido a la no compactación y desorganización de los datos. La forma de organización del Stack (LIFO) permite mitigar la fragmentación si se utiliza una buena gestión de memoria. Con el Heap no es posible evitar la fragmentación debido a que no tiene un comportamiendo predecible que garantice que los datos estén compactados y ordenados. El Heap no hay garantías de que los elementos serán removidos en un orden específico ni que estén ordenados de forma compactada. Es decir el Heap requiere tiempo de procesamiento variable debido a que los datos almacenados pueden ser de distinto tamaño, necesitando de tiempos variables para su procesamiento.
Para mitigar esta fragmentación, en el Heap es necesario verificar si existen agujeros en los bloques de memoria previamente asignados, para evitar realizar una llamada al sistema y reutilizar la memoria disponible. Para esto el Heap recurre a tres estrategias principales.
Una estrategia encontrar el primer agujero disponible con la capacidad para almacenar el dato (first fit). Es la más rápida pero no reduce la fragmentación. La segunda es encontrar el agujero lo más pequeño posible que permita almacenar el valor (best fit) y finalmente encontrar cualquier agujero disponible con la capacidad más grande que permita almacenar el dato (worst fit). Ambas podrían reducir la fragmentación pero no son las más rápidas. El uso de estas estrategias no evitan la fragmentación y la elección depende de factores como la rapidez y los pros y contras de cada solución.
Listas enlazadas en el Heap
El Heap no resuelve el problema de sobre escribir elementos de un arreglo. Para esto se utilizan estructuras de datos como listas enlazadas de punteros. Donde se tienen nodos que mantienen un puntero asociado al siguiente nodo. Es decir se crea un nuevo nodo (asignando memoria en el Heap) y se añade a la lista, modificando el elemento anterior con el puntero al nuevo nodo. Lo que soluciona esta estrategia es que no se necesitan bloques continuos en la memoria. El principal problema es que los nodos distribuidos por la memoria tienen menos probabilidad de almacenamiento en caché del CPU. Por lo que se debe priorizar compactar los datos.
Llamadas al Sistema
Por temas de seguridad el sistema operativo no permite acceder directamente al hardware. Por lo que para solicitar recursos los programas deben realizar llamadas al sistema operativo.
El siguiente programa en C muestra un "hola mundo" tradicional.
#include <stdio.h>
int main() {
// Mostramos el mensaje con printf
printf("¡Sistemas Operativos!");
return 0;
}La función printf (print format) es una abstracción, una capa a la llamada del sistema
que le dice al sistema operativo que muestre el mensaje en la salida estándar.
Esta función formatea el texto para ser finalmente invocada la función write
que eventualmente llama a la función syscall con los datos respectivos.
#include <unistd.h>
int main(void) {
write(1, "¡Sistemas Operativos!\n", 22);
return 0;
}#include <unistd.h>
#include <sys/syscall.h>
int main(void) {
syscall(SYS_write, 1, "¡Sistemas Operativos!\n", 22);
return 0;
}Lo que se traduce en código de bajo nivel similar al siguiente
int main(void) {
register int syscall_no asm("rax") = 1;
register int arg1 asm("rdi") = 1;
register char* arg2 asm("rsi") = "¡Sistemas Operativos!\n";
register int arg3 asm("rdx") = 22;
asm("syscall");
return 0;
}Estos son mecanismos de bajo nivel utilizados para estandarizar el acceso a archivos, memoria y otros recursos del sistema, con el fin de permitir la interoperabilidad de forma controlada, lo que asegura la integridad del sistema. Debido a eso, el acceso a los recursos del sistema es lo que llamamos acceso privilegiado y solo puede ser realizado por el sistema operativo. El programa de usuario solicita que el sistema operativo proporcione ese acceso a través de un servicio bien definido. Entonces, asumiendo que el servicio se haya solicitado correctamente, se proporcionará dicho servicio (Burt K, s.f.).
Coste de las llamadas a sistema
Lo importante a destacar de las llamadas al sistema es que tienen un costo en términos de desempeño. Cuando un programa se ejecuta el proceso asociado tiene un estado en los registros de la CPU (El Program Counter, entre otros). Como el sistema operativo debe administrar diferentes procesos, debe guardar el estado en memoria de cada uno. Es como si tomara una fotografía de la información (El contexto de ejecución, execution context) de cada proceso y lo almacenara en memoria para ser obtenido luego de ejecutar la operación solicitada. El constante cambio entre los diferentes contextos de proceso se conoce como "cambio de contexto" (context switch).
Se podría resumir en las siguientes etapas:
-
El proceso es iniciado.
-
El proceso ejecuta una llamada al sistema (syscall).
-
El sistema operativo guarda el estado en memoria del proceso.
-
El sistema operativo ejecuta la llamada de sistema.
-
El sistema operativo carga el proceso y le entrega el resultado de la llamada al sistema.
-
El sistema operativo cambia de contexto a otro proceso que solicite otra llamada al sistema.
¿El Heap es más lento que el Stack?
Como se puede apreciar todas las etapas de gestión de procesos del sistema operativo toman tiempo, recursos y perjudican el desempeño. Cuando un proceso requiere más memoria, se debe utilizar una llamada al sistema. La memoria asignada al Stack está predefinida al iniciar el proceso, por lo que no requiere solicitar más memoria al sistema operativo utilizando llamadas de sistema. El sistema operativo puede necesitar más tiempo en encontrar secciones de memoria disponible para el Heap, por lo que puede haber penalizaciones de tiempo y en el peor de los casos disminuir el desempeño de los programas, causando lentitud en los mismos. Pero esto no significa que usar Heap sea más lento que usar el Stack. Lo que causa lentitud es todo el proceso de asignación de memoria, pero una vez que ya está asignada y con técnicas de gestión de recursos como el caché y estructuras de datos eficientes, utilizar el Heap puede ser tan rápido como usar el Stack.
ALU
Una unidad aritmética lógica (Arithmetic Logic Unit) toma valores de entrada (OPERANDS) y códigos de operación (OP_CODES) y a través de circuitería (Adder, Subtracter, Incrementer, Decrementer, Decoder, entre otras) y compuertas lógicas (XOR, AND, OR, NOT, entre otras), determina la operación que se debe realizar con esos valores. Finalmente retorna el resultado (Result) de la operación junto a información adicional (Si fue negativo, cero o hubo un desbordamiento).
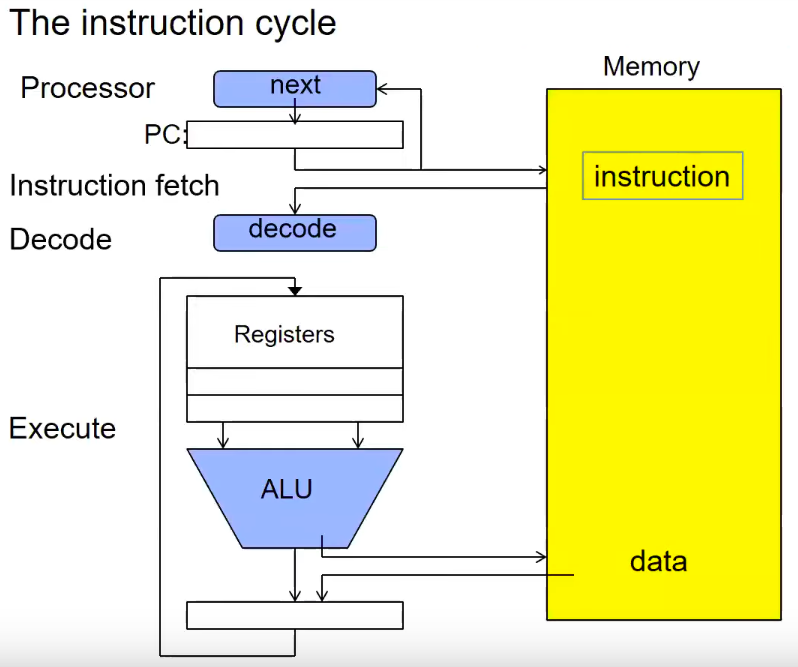
El Ciclo de Instrucción
Una instrucción en el procesador tiene un ciclo de obtener, decodificar y ejecutar.
-
El procesador utiliza la posición de puntero almacenada en el
PC(Program Counter) para leer la siguiente instrucción a procesar desde la memoria. -
Luego esta instrucción es decodificada. Obteniendo los registros correspondientes.
-
Finalmente se envía a la cadena de ejecución, la cual depende de cada procesador (por ejemplo para arquitecturas RISC-V son 5 etapas). Acá es utilizada la ALU para obtener el resultado.
-
El ciclo se repite modificando el
PCpara obtener la siguiente instrucción a procesar. Un procesador puede ejecutar millones de instrucciones por segundo.
El siguiente video muestran el funcionamiento de las compuertas lógicas y la ALU.
Actividades
En esta actividad se practicará la creación de scripts con Bash, las diferencias entre root (administrador) y usuario común y la instalación de programas en Debian Linux con el gestor de paquetes apt.
-
Instalar Debian en una máquina virtual
-
Instalar editor Gedit (
# apt install gedit -y). -
Seleccionar un ejercicio resuelto de la sección 2.30 del libro Enrique Soriano, crear un archivo y ejecutarlo con (
$ chmod +x). -
(Opcional) Realizar los ejercicios no resueltos de la sección 2.31 del libro Enrique Soriano. Ejercicio 7 y Ejercicio 11.
Foro
En un mínimo de 150 palabras y un máximo de 350 palabras. Responda lo siguiente:
¿Por qué un Hilo (Thread) es una abstracción de una CPU?
Incluya introducción, desarrollo, conclusión y referencias bibliográficas (al menos 2) formato APA 7. Comente la respuesta de dos de sus compañeros (con referencias en APA 7).